Context isn't overhead. It's the product.
I've been building a lot of sample apps lately, and testing different ways to work with agents along the way. It's easy to get lost in the noise: MCP servers, skills, new AI tools every day, and the constant question of whether to use Claude, Copilot, Codex, or something else.
But after all that, one thing has made the biggest difference in the quality of the output: context.
So I wanted to share the setup that has been working best for me. Yours might look different: fewer files, different names, a different order. That's not the point. The structure matters less than the habit behind it.
Quick note: when I say "context files," I mean plain markdown: .md files in your project root that an agent like Claude Code or Cursor reads before doing any work.
That's the whole argument: context isn't overhead. It's the product.
Why "Just Prompt Better" Is the Wrong Answer
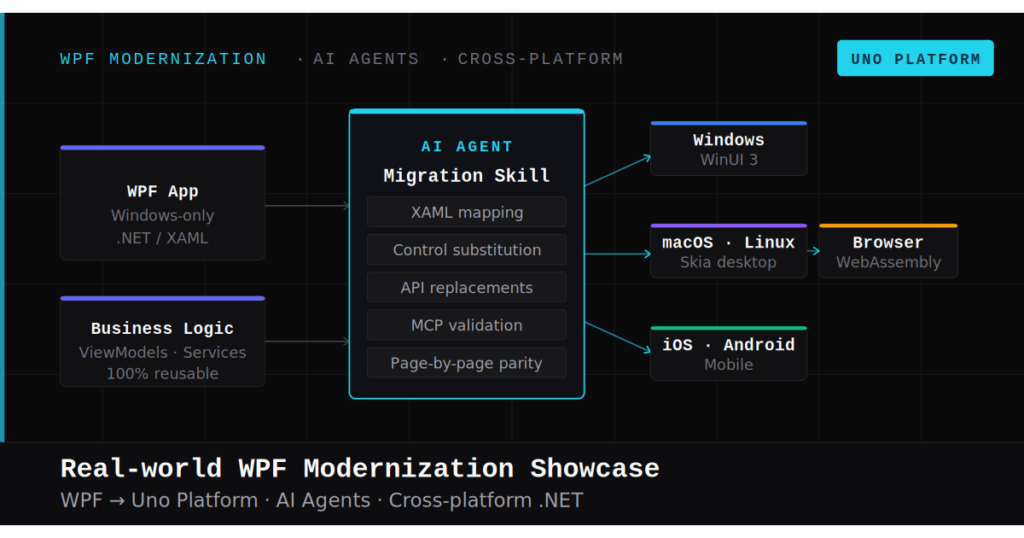
Two engineers on the same cross-platform .NET project ask the same AI agent to build the same feature. One gets something generic that compiles and feels like every other agent-generated screen. The other gets something that fits the product, follows the conventions, picks up the right components and the right MVUX patterns, and lands close enough to merge.
Same model. Same prompt. Different results.
The difference wasn't a better model. It wasn't a secret prompt. It was that one engineer treated the agent like a Stack Overflow query, and the other treated it like a teammate joining on day one.
The prompt-engineering frame assumes a transactional model: input prompt, output code. That model fits autocomplete. It does not fit building.
Building requires sustained context across hundreds of decisions: naming, spacing, navigation patterns, error states, what to log, what not to abstract. Most of those decisions never appear in any single prompt. They live in the team's shared sense of how things are done here.
So the real question isn't "what's the best prompt?" It's "what does an agent need to know to make decisions the way our team would?" And the honest answer is: the same thing a new teammate needs. Just written down.
What I started doing instead: treating project documentation as the place where agent alignment happens. This isn't new in spirit. Good engineering teams have always written down architecture decisions, conventions, and intent. What's new is that those documents now have a second reader.
The README that helps a new hire ramp up in week one is the same document that gives an agent enough context to make sensible choices in week two. The architecture notes that prevented a junior engineer from re-introducing a deprecated pattern are the same notes that stop the agent from doing it.
Stop writing two kinds of docs: one for humans, one as prompt scaffolding. Write one kind, well.
The Composition Stack
I broke down my project into six markdown files an agent reads at session start, twenty-five sections in total, each earning its place. They're the project's shared mental model, readable by both humans and agents.
Foundation: README.md + CLAUDE.md
The first thing anyone reads on day one. README is the what: what this is, who it's for, what runs it. CLAUDE.md is the how: conventions, rules, settings, what we prefer, what we've already tried and rejected.
Example: "Prefer x:Bind over {Binding}. Default to MVUX for app state, MVVM for sample pages. Never edit generated files."
I'm using Claude Code as the reference here, so you'll see CLAUDE.md in the list. The same surface exists in Cursor (.cursorrules), GitHub Copilot (custom instructions), Codex, and most other coding agents. The filename changes, the role doesn't.
Wiring: .mcp.json + ux-flows.md
The connectors that turn a model into a teammate. .mcp.json lists the tools the agent can actually call: your linter, your docs server, your design system index. ux-flows.md describes the primary user paths that thread through those tools.
Example: A four-line list: "Sign in -> Today screen -> Open job -> Mark complete -> Sync queue."
Design System: design.md
Tokens, palettes, typography, spacing, components. The constraints that make a hundred screens feel like one product.
Example: "Body text is BodyMedium. Touch targets >= 48dp. Card elevation is reserved for items the user can act on. Don't introduce a new color."
Interactions: interactions.md
Animations, transitions, motion, state changes. The rules for how the product feels.
Example: "Page transitions are 240ms ease-out. Skeletons appear after 200ms, never sooner. Snackbars are for confirmation, not error."
Architecture: architecture.md
Data flow, patterns, libraries. The decisions every other layer in this stack assumes.
Example: "Network calls go through IApiClient. UI never touches HTTP directly. Region-based navigation, one ContentControl host per shell."
Plan: plan.md
Goals, phases, tasks. The vague intent turned into something an agent can scaffold and execute against.
Example: "Phase 1: read-only inventory view. Phase 2: edit + sync queue. Phase 3: barcode scanner. Don't scaffold phase 2 work into phase 1 files."
The point isn't the exact filenames. The point is the structure: six surfaces, each answering a different question, each addressable on its own.
The composition stack, visualized: six layers from Foundation through Plan.
What This Gets You That Prompts Don't
Continuity across sessions. Prompts are stateless. Documents persist. When an agent picks up work three days later, it reads the same files it read last time. Your team's shared understanding is durable instead of something you re-type into every conversation.
Visibility for humans. The documents that help the agent are the same ones that help your team. There's no parallel "AI prompt library" to maintain, no separate truth that drifts. New engineers benefit from the same investment. So does the agent. So does the version of you who comes back to this codebase in four months.
Composability. Each layer answers a different question. When you're debugging a layout issue, you reach for design.md. When you're adding a new tool, you reach for .mcp.json. The agent triages the same way. Context becomes addressable instead of a giant blob you reload every session.
Here's a concrete example: last week I asked the agent to add a new settings page to a project that had the stack set up. I didn't re-explain anything. It inherited spacing from design.md, the navigation host pattern from architecture.md, and the destination tone (terse, utility-first) from CLAUDE.md. The PR was small enough to review without scrolling. That's not the model getting smarter. That's the model getting context.
What This Doesn't Solve
Honest section. I've watched this approach fail in three predictable ways. None of it is magic.
It won't fix a bad idea. If the intent in your README is wrong, every layer below it inherits the wrongness. The composition stack is a multiplier, not a corrector.
It won't replace taste. The system makes "on-brand" a build step, but someone still has to define what "on-brand" means. The agent can follow design.md. It can't write it for you.
And it has a discipline cost. Documents drift if no one tends them. The composition stack only works if it stays alive. A stale architecture.md is worse than no architecture.md, because now the agent is confidently wrong.
The Mental Shift
When you treat context as architecture, every other part of the work changes. When you write a feature, you also write the conventions that explain it. When you choose a library, you also explain the choice. The artifacts of thinking become the artifacts of building.
This is the part of engineering that used to live in heads, in DMs, in tribal knowledge passed down across standups. The composition stack pulls it into the open, where both humans and agents can use it. That's a productivity story, but more importantly, it's a continuity story. The next person on this codebase, whether they're a junior, a contractor, or an agent, gets the same starting line you did.
The shift isn't "now I prompt better." The shift is "now I write differently."
Close
Back to the two engineers.
The one who got the better result didn't have a secret prompt. They had a system. Six files. Each one earned its place. Each one read by humans and agents alike. The agent didn't know more; it was given more.
When agents see the connections, they can navigate the work.
Context isn't overhead. It's the product.
Use Mine to Start
If you want to skip the blank page, I put together a starter repo with the six files pre-filled: README, CLAUDE.md, plus the architecture, design, interactions, and plan briefs I actually use on Uno Platform projects.
Clone it, take what fits, leave what doesn't. The structure matters less than the habit behind it.